Bots, Bots, Bots und KI
Vor gut zwei Jahren hatte ich über Bot-Besuche im Open-Data-Portal geschrieben. Mitlerweile hat sich die Situation start verändert. Ging es damals um tausende Zugriffe, so sind es heute Millionen. Was hat KI damit zu tun?
Damals lautete der Titel meines Beitrags noch Kommt ein Bot zu Besuch. Heute müsste es eher heißen: Stürmt eine Horde Bots mein Haus. Doch der Reihe nach. Vor genau einem Monat habe ich über eine Logfile-“Explosion” geschrieben. Obwohl der Portal-Betreiber Gegenmaßnahmen (Rate-Limits) getroffen hat, ist die Zahl der Zugriffe mit 25 Millionen immer noch wahnsinnig hoch. Ich wollte genauer wissen, was die Ursache dafür sein könnte.
Früher war es einfach, Bots zu erkennen. Sie hatten in der User-Agent Kopfzeile irgendetwas mit Bot oder bot stehen, z.B. GoogleBot oder bingbot. Heute heißen diese Programme auch Bytespider, GoogleOther oder ChatGPT-User und werden daher von einigen Programmen zur Logfile-Analyse nicht mehr erkannt. Also habe ich mir ein eigenes Python-Programm geschrieben, das mit Hilfe der (apachelogs)[https://pypi.org/project/apachelogs/]-Bibliothek (die auch für nginx-Webserver funktioniert) die Logfiles analysiert.
Bis etwa August 2023 entwickelten sich die Zugriffszahlen normal, ab September 2023 begann der starke Anstieg. Damit wir in jedem Fall auf der sicheren Seite sind, schauen wir uns ein Diagramm der Bots vom Juli 2023 an:
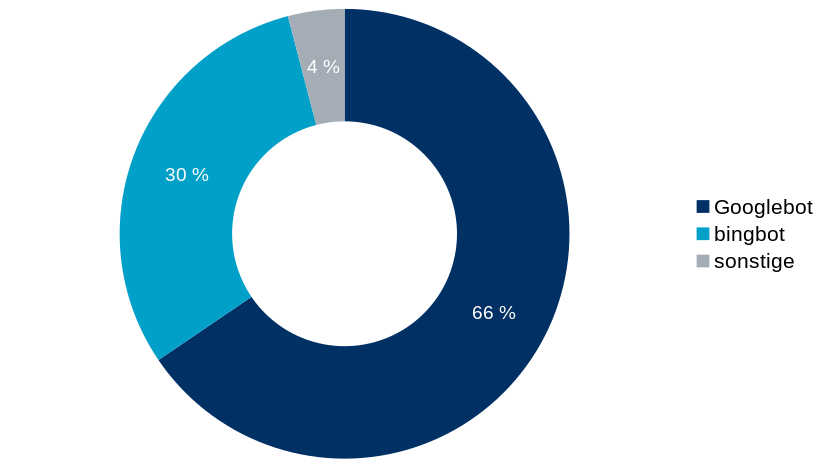
Die Gesamtzahl der Zugriffe lag bei 2,3 Millionen, der Anteil der Bots daran bei 48%. Das sind Werte, die ich so seit vielen Jahren kannte.
Im September 2023 beginnt sich die Situation zu verändern:
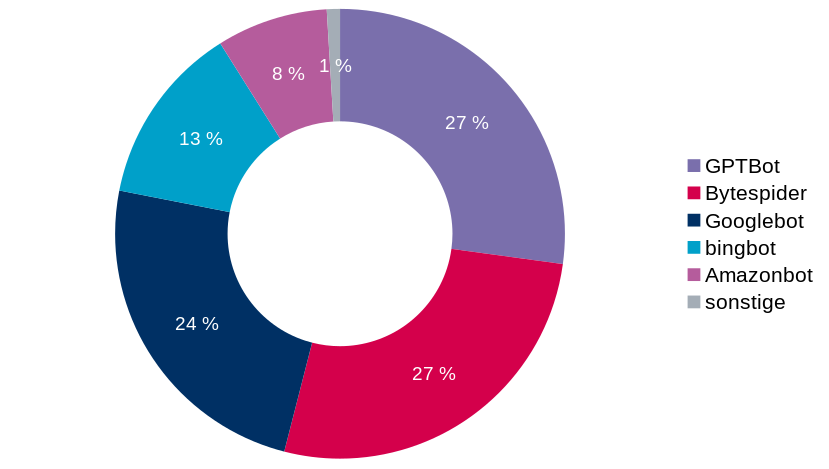
Der Googlebot ist noch wie in alten Zeiten unterwegs, die absoluten Zahlen haben sich kaum geändert. Aber es sind ganz neue Mitspieler aufgetaucht: der GPTBot, der Bytespider (vom chinesischen Betreiber von TikTok) und der Amazonbot. Der Anteil der Botzugriffe ist mit 50% noch im normalen Rahmen. Schauen wir zwei Monate weiter in den November 2023:
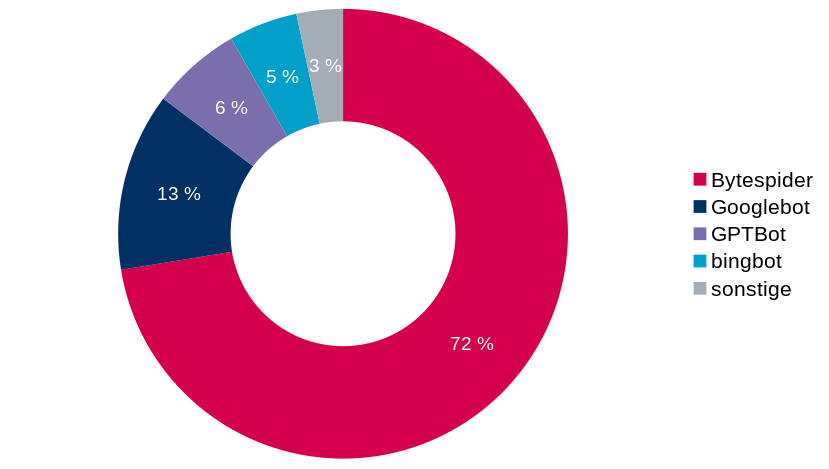
Die Zugriffe aus China machen nun schon über die Hälfte aller Zugriffe und fast Dreiviertel der Botzugriffe aus. Insgesamt liegt der Anteil der Bots am Gesamtaufkommen bereits 72%. Dies wird sich bis März 2024 aber noch steigern:
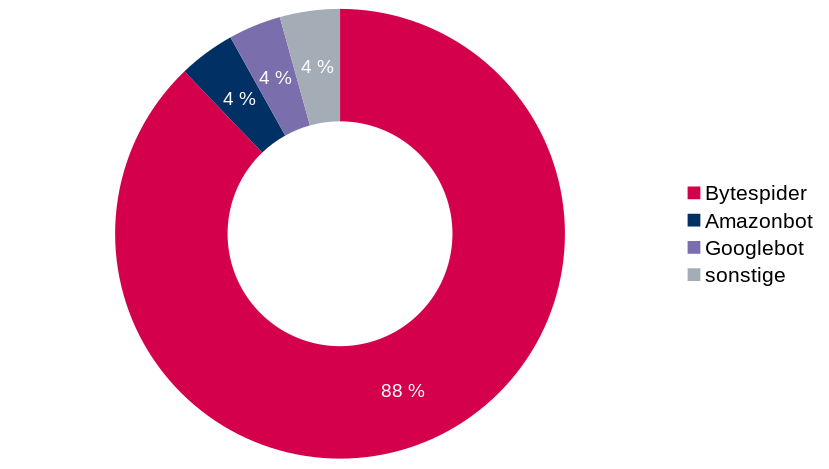
Fast 80% aller Zugriffe erfolgen nun durch Bytedance. Anders als seriöse Webcrawler kümmern man sich dort auch nicht um in der robots.txt vorgeschlagene crawl delays. Von einer Vielzahl von IP-Adressen aus wird ziemlich ziellos alles immer und immer wieder abgerufen. Insgesamt kommen nun 91% aller Abrufe von wenigen Bots.
Kann es noch schlimmer werden? Ja. Denn auch auf der anderen Seite des Pazifiks gibt es schlechte Entwickler:innen, die mit Rechenleistung und Bandbreite auf alles draufhauen. Hier das Diagramm für den April 2024 mit einem Bot-Anteil an den Aufrufen von 97%:
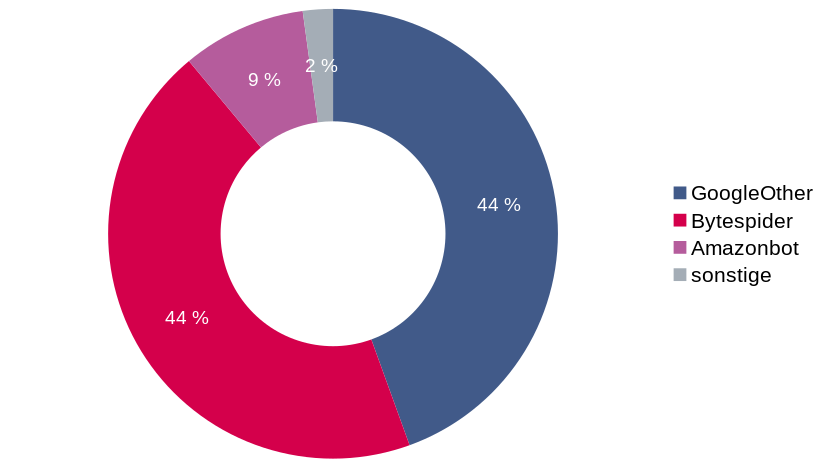
Obwohl der Google-Bot seine absoluten Zugriffszahlen fast verdoppelt hat, steckt er nun unter sonstige, zusammen mit dem GPTBot und dem bingbot. Es ist aus den USA ein neuer Rüpel unter den Bots aufgetaucht, der sich ähnlich rücksichtslos verhält, wie sein Kollege aus China: GoogleOther. Laut der Beschreibung von Google handelt es sich dabei um einen Webcrawler, der intern von verschiedenen Google Teams verwendet wird.
Schauen wir auf das aktuelle Diagramm vom Mai 2024:
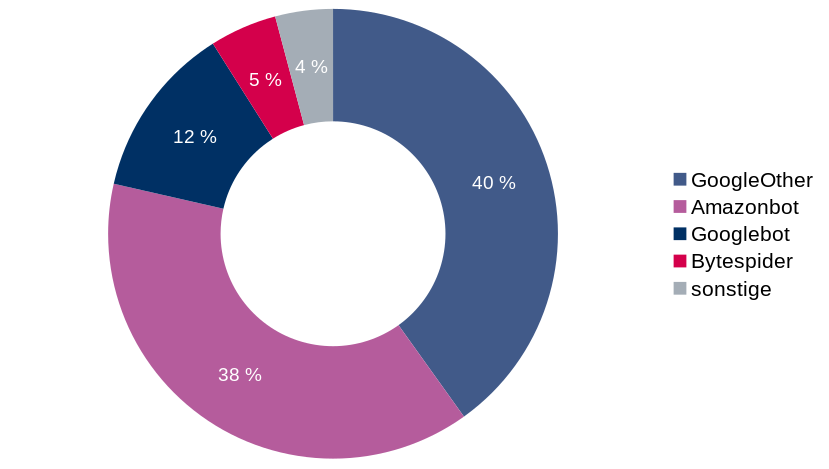
Bytedance scheint seinen Wissensdurst mehr oder weniger gestillt zu haben. Aber eine weitere Firma hat kräftig aufgedreht: Amazon. Auch der reguläre GoogleBot ist wieder deutlich stärker vertreten.
Was steckt dahinter? Meine Vermutung ist, dass hier für das Training von large language models (LLM) Daten beschafft werden. Dazu passt auch gut die Tatsache, dass die Aktivitäten von Firmen wie OpenAI, Google, Bytedance und Amazon ausgehen - alles Größen im Bereich KI. Wie immer bei KI stehen dafür so massiv Resourcen zur Verfügung, dass man bei der Software-Entwicklung sparen kann. Schlechte Entwicker:innen schreiben schnell einen Crawler, starten den hundertfach “in der Cloud” und schauen, was passiert. Die Leidtragenden sind die Webseitenbetreiber, deren Inhalte auch noch in die KI-Modelle übernommen werden. Bei Open Data mag das ja in Ordnung sein, aber etwas rücksichtsvoller könnte man schon vorgehen.
Ich bin schon gespannt, wie das weitergehen wird. Da die Zugriffe aus großen Cloudsystemen erfolgen, ist auch ein rate limit (z.B. nur 10 Zugriffe pro Sekunde, danach werden Antworten verzögert) schwierig. Im schlimmsten Fall kommt von einer IP-Adresse aus nur eine Anfrage und dann geht es mit einer anderen IP-Adresse weiter. Möglicherweise ist der Spuk in ein paar Wochen auch wieder vorbei, da dann das Training für die LLMs abgeschlossen ist.
Kommentare
Mit einem Konto im Fediverse oder auf Mastodon kannst du auf diesen Beitrag antworten. Da Mastodon dezentral funktioniert, kannst du dein bestehendes Konto auf einem Mastodon-Server oder einer kompatiblen Plattform verwenden.
Nach einem Klick auf "Lade Kommentare" werden nicht-private Antworten vom Server norden.social geladen und unten angezeigt.
Wie das technisch funktioniert, kann man hier erfahren.