Ausblick auf die Open-Data-Infrastruktur Schleswig-Holstein
Das Land Schleswig-Holstein arbeitet momentan an einer modularen Infrastruktur für offene Daten. Aus welchen Komponenten diese besteht, möchte ich in diesem Beitrag erläutern.
Vor einigen Wochen gab es bei den Kieler Open Source und Linux Tagen einen Vortrag zum Thema „Open-Data in SH: Aktueller Stand und Ausblick“. Den Vortrag kann man sich unter https://tube.tchncs.de/w/vZ9yxidfmy4jJ2uCSCryqT ansehen.
Damit man etwas zum Lesen/Verlinken/Diskutieren hat, möchte ich die einzelnen Komponenten der geplanten Open-Data-Infrastruktur an dieser Stelle in Textform beschreiben.
Die ganze Open-Data-Infrastruktur ist modular aufgebaut. Es gibt Hersteller, die einem ein Komplettsystem verkaufen wollen – von dem kommt man aber nur mit großem Migrationsaufwand wieder weg. Um diesen vendor lock-in zu vermeiden, wird bei der Open-Data-Infrastruktur auf einzelnen Komponenten gesetzt, die man bei Bedarf auch wieder austauschen kann.
Schema-Repository
Daten sind nur dann sinnvoll nutzbar, wenn sie maschinenlesbar und technisch korrekt sind. Beides lässt sich erreichen, indem man zusätzlich zu den Dateien mit den Daten (z.B. CSV-Dateien) maschinenlesbare Beschreibungen erstellt, wie die Dateien aufgebaut sind, sogenannte Schemata Wir werden die Frictionless Specification als Grundlage dieser Beschreibung verwenden. Wir sind damit nicht alleine, u.a. Frankreich verwendet Frictionless Specification für ihre offene Daten. Die Frictionless Specification ist sehr flexibel und ermöglicht eine große Bandbreite von einfachen Angaben, welches Trennzeichen für eine CSV-Datei verwendet wird bis hin zu detaillierten Angaben zu erlaubten Werten, die in einer Spalte vorkommen können. Außerdem gibt es Bibliotheken für diverse Sprachen, um mit so beschriebenen Daten arbeiten zu können.
Das Schema-Repository ist der zentrale Ablageort für Schemata. So kann man sie leicht finden und referenzieren. Da sich Beschreibungen im Laufe der Zeit weiterentwickeln (neue Spalten kommen hinzu, Werte werden ergänzt etc.) benötigt man auch eine Versionierung für Schemata. Auch dies soll das Schema-Repository bieten.
Vorbild ist dabei schema.data.gouv.fr, das französische Schema-Repository. Dabei handelt es sich um Open-Source-Software, die wir im Idealfall nutzen und ggf. weiterentwickeln können.
Staging-System
In vielen Fällen müssen Daten für die Veröffentlichung erst vorbereitet werden. Für Datensätze müssen Metadaten erfasst werden. Eventuell müssen Datensätze bewertet werden, um Aufbereitungen (Qualitätssicherung, Anonymisierung etc.) zu priorisieren. Zu Dateien müssen Metadaten erfasst werden, um die Struktur und die enthaltenen Daten zu beschreiben. Möglicherweise müssen Daten noch Bereinigt werden, da sie Tippfehler o.ä. enthalten.
Bei diesen Arbeitsschritten soll das Staging-System unterstützen. Ob es eine einzige Software wird, oder ob es sinnvoller ist, für verschiedene Arbeitsschritte unterschiedliche Software zu verwenden, muss noch im Laufe des Projekts geklärt werden.
Auch hier gibt es mit publier.etalab.studio eine existierende Open-Source-Lösung aus Frankreich, die wir uns ansehen werden.
Workflowsystem für ETL
Digitalisierung lebt von Automatisierung. Wenn ein Datensatz ins Portal geladen wird, müssen automatisch im Hintergrund Aktionen ausgeführt werden. Es müssen Parquet Datei geschrieben werden der Triplestore muss aktualisiert werden, evtl. muss ein Geodienst Geodienst erzeugt werden, und und und
Daher werden wir mit Hilfe von Apache NiFi ein Workflowsystem für ETL (Extract, Transform, Load) aufbauen, um diese Datenverarbeitungen automatisch durchzuführen.
Visualisierungen
Bisher spielte die Darstellung von Daten im Open-Data-Portal keine Rolle. Auf ausdrücklichen Wunsch der Datenlieferanten sollte das Portal nur eine Quelle der unbearbeiteten Rohdaten sein. Visualisierungen wollte man immer selbst erstellen. Man fürchtete sich möglicherweise um einen Verlust über die Deutungshoheit der Daten. Man kann sagen, dass sich diese Einstellung um 180° gedreht hat. Nun werden Visualisierungen der Daten gewünscht.
Daher sollen Komponenten ausgewählt/erstellt werden, die das Erzeugen von Diagrammen aus aktuellen Daten ermöglichen. Diese sollen in anderen Webseiten einbettbar sein. So hätte eine Kommune die Möglichkeit, Daten im Open-Data-Portal bereitzustellen und dann bequem auf der eigenen Webseite ein Diagramm einzubetten, das diese aktuellen Daten darstellt. Es wäre lokal keine IT-Infrastruktur mehr dafür notwendig.
Als eine mögliche Software haben wir hier Metabase im Blick.
Semantische Technologie (SPARQL-Endpunkt)
Bei der Bereitstellung offener Daten wollen wir semantische Technologien nutzen und sowohl Metadaten als auch Daten als Linked Open Data bereitstellen.
Eine SPARQL-Abfrage in Metadaten bereits üblich, z.B. bei GovData und im europäischen Datenportal. Das sieht dann etwa so aus:
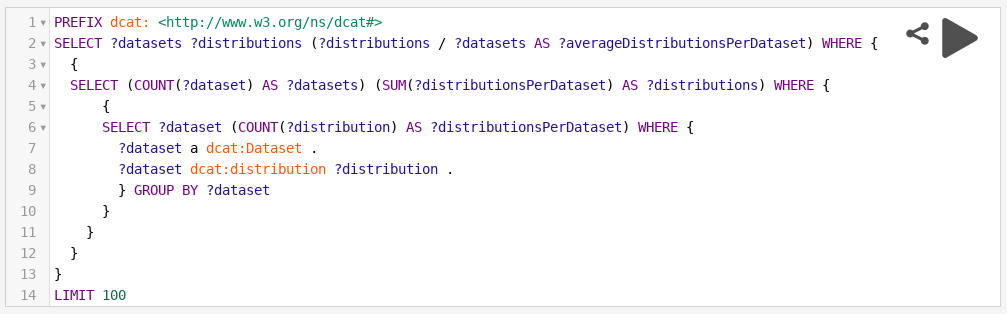
Wir wollen jedoch auch Daten in den Triplestore legen. Dabei ist klar, dass kaum ein Fachverfahren von sich aus semantische Daten (RDF, Triples) erzeugen wird. Daher wird unsere Lösung auch eine Möglichkeit enthalten, aus CSV-Dateien heraus Linked Open Data anbieten zu können. In meinem Blog-Beitrag Von 3 auf 5 habe ich schon davon geschrieben, wie das funktioniert. Damit das bei jeder Aktualisierung der Daten funktioniert benötigen wir wieder die schon oben erwähnte ETL-Strecke.
Dynamische Daten
Manche Daten bringen besonders dann viel Nutzen, wenn sie zeitnah verfügbar sind. Es ist zwar interessant, wie ein Parkplatz letzte Woche belegt war, und auch für das Trainieren statistischer Modelle sind Zeitreihen notwendig, aber so richtig interessant ist doch eigentlich der Wert wie der Parkplatz jetzt belegt ist. Zudem zeichnen sich dynamische Daten dadurch aus, dass nicht gleich ein ganzer Datensatz geändert wird sondern es nur kleine Änderungen von Werten gibt. Dafür muss nicht gleich der ganze Datensatz angepasst werden.
Wir haben unterschiedliche Signale bekommen, auf welche (offene) Technik wir dabei setzen sollten. Während die Stadt Hamburg auf SensorThingsAPI und den FROST-Server setzt, haben einige Kommunen in Schleswig-Holstein auf FIWARE basierende Systeme im Einsatz. Wir werden daher beide Technologien erproben und an ganz konkreten Anwendungsbeispielen darstellen, was zu tun ist, um das System von Null in den Betrieb zu kommen, Daten einzufügen und Daten wieder auszulesen. Dadurch bekommen wir hoffentlich einen guten und realistischen Eindruck davon, welche Technologie für uns am besten geeignet ist. Natürlich sollen die Ergebnisse offen allen Interessierten zur Verfügung gestellt werden, so dass sich jeder selbst ein Bild machen kann.
Daten in Open Table Format
Bislang ist es üblich Daten als CSV-Dateien anzubieten. In Kombination mit der Beschreibung als Tabular Data Resource lassen diese sich dies auch schon gut maschinell verarbeiten. Aber gerade große Mengen Daten werden als CSV-Datei eher unhandlich. In den Datendialogen, die im Jahr 2023 durchgeführt wurden, wurde insbesondere aus der Wirtschaft der Wunsch an uns herangetragen, Daten auch in einem Open Table Format anzubieten. Diesem Wunsch kommen wir gerne nach und werden Daten auch im Apache Parquet Format anbieten. Auch da sind wir im Bereich Open Data nicht die Ersten, in Frankreich gibt es bereits Datensätze im Parquet Format, z.B. die Bureaux de vote et adresses de leurs électeurs
Parquet-Dateien sind deutlich kleiner als CSV-Dateien, statt 1,8GB CSV-Datei ist die Parquet-Datei nur 470MB groß. Wirklich cool ist aber, dass Parquet eine Art „SQL-Suche in Dateien“ ermöglicht, ohne dass es auf Serverseite dazu eine Datenbankserver braucht. Man kann quasi die SQL-Anfrage direkt an die Datei stellen - und das sogar im Browser. Das kann man auf schell.duckdb.org selbst ausprobieren:
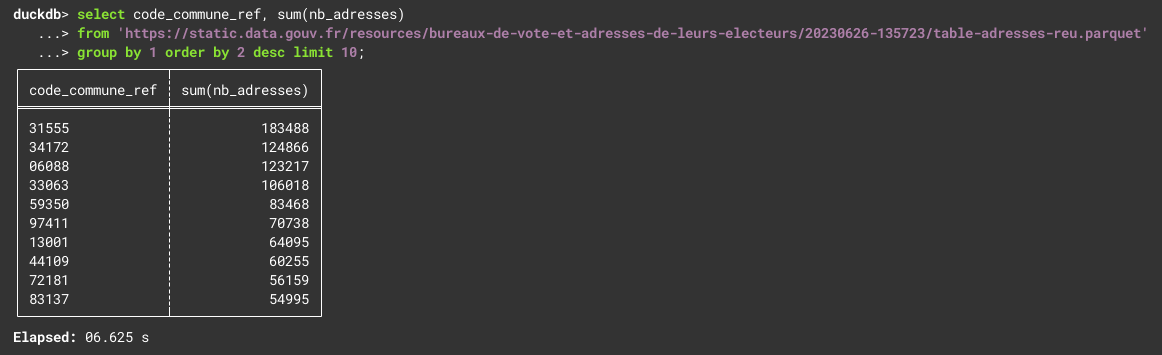
Wie man an der Antwortzeit schon erkennen kann, wurden dabei nicht die kompletten 470MB übertragen. Die Parquet-Dateien sind so geschickt aufgebaut, dass nur ein Teil der Datei abgerufen werden muss. Ein Blick auf die Netzwerkanalyse des Browsers bestätigt dies:
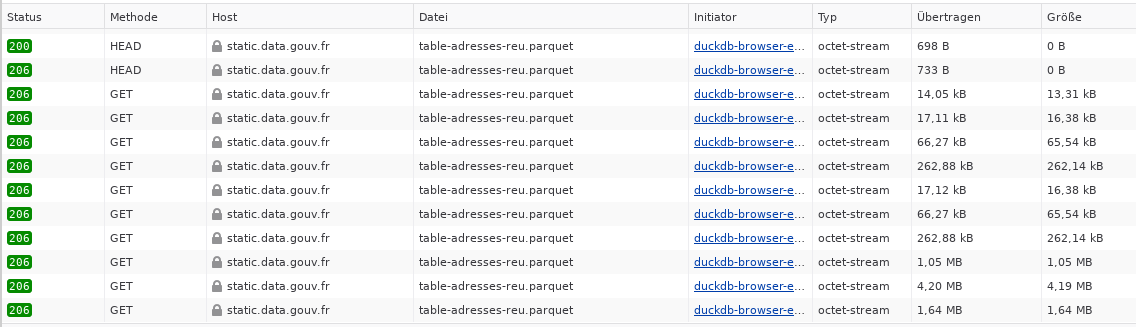
Verbesserungen im Portal
Zu guter Letzt werden wir auch noch einige Verbesserungen im Open-Data-Portal vornehmen. Wichtig wird im Jahr 2024 die Anpassung an die neue DCAT-AP.de Version 3, die vermutlich in diesem Jahr veröffentlicht werden wird. Eine wichtige Änderung dabei ist die Anpassung des Datenmodells in Richtung “Geowelt” mit Datensatz, Datensatzserie und Dienst.
Schon im Projekt Data Go - Open Data zu GovData (der Ergebnisbericht zu Data Go ist auf den Seiten des IT-Planungsrats zu finden) wurde überlegt, ob es nicht besser ist, statt CKAN auf eine andere Software für ein Open-Data-Portal zu setzen. Ein zentrales Problem bei CKAN ist das Datenmodell, das nicht wirklich zu DCAT-AP passt. Damit einher geht Datenverlust, der bei der Konvertierung DCAT-AP → CKAN → DCAT-AP entsteht.
Eine Alternative zu CKAN ist Piveau, eine von Fraunhofer FOKUS entwickelte Open-Source-Software, die auch für das europäisches Datenportal und das Open-Data-Portal Bayern eingesetzt wird. Es wurde direkt für DCAT-AP entwickelt und speichert daher seine Daten direkt in einem Triplestore, so dass man keinen Datenverlust durch Konvertierung mehr fürchten muss. Es wird momentan eine Piveau-Installation im Schleswig-Holstein-Design mit einigen Anpassungen vorbereitet, so dass wir einen besseren Eindruck davon bekommen, in wie weit die Funktionalitäten des aktuellen Open-Data-Portals von Piveau abgedeckt sind und was noch entwickelt werden müsste.
Kommentare
Mit einem Konto im Fediverse oder auf Mastodon kannst du auf diesen Beitrag antworten. Da Mastodon dezentral funktioniert, kannst du dein bestehendes Konto auf einem Mastodon-Server oder einer kompatiblen Plattform verwenden.
Nach einem Klick auf "Lade Kommentare" werden nicht-private Antworten vom Server norden.social geladen und unten angezeigt.
Wie das technisch funktioniert, kann man hier erfahren.