Kernkraftfernüberwachung
Seit einigen Wochen gibt es im Open-Data-Portal Schleswig-Holstein Daten zur Kernkraftfernüberwachung (KFÜ). Was sind das für Daten und wie kann man mit ihnen arbeiten?
In Schleswig-Holstein gibt es im Bereich der abgeschalteten Atomkraftwerke Brunsbüttel, Brokdorf und Krümmel ein Messnetz zur Erfassung der Gamma-Ortsdosisleistung. Neben einer Darstellung auf einer Karte werden seit dem 9. Februar 2023 auch die stündlichen Messdaten als CSV-Dateien zur Verfügung gestellt. Da es nicht ganz einfach ist, den Aufbau der CSV-Dateien zu verstehen, möchte ich hier ein paar Hinweise geben.
Wenn man sich im Open-Data-Portal die Datenserie der KFÜ-Messwerte ansieht, erkennt man, dass die Daten jeden (Werk-)Tag jeweils für 7 Tage in der Vergangenheit geliefert werden. Das heißt die Messwerte in den Dateien überschneiden sich. Man benötigt also theoretisch nur einen Teil der Datensätze, um eine komplette Zeitreihe zu bekommen.
Struktur einer Datei
Eine jede CSV-Datei ist in drei Bereiche untergliedert:
- stündliche Messwerte mit einer Spalte pro Messstation/Messwert
- Liste der Messstationen
- Kommentare zu einzelnen Datenpunkten
Wie man leicht ausrechnen kann (7x24) enthält jede Datei im ersten Bereich 168 Messwerte.
Im ersten Block wird Semikolon als Spaltentrenner verwendet. Der Bock beginnt mit zwei Zeilen Überschrift, wobei die zweite Zeile nur die Maßeinheit enthält. Nach den 168 Zeilen mit den Messwerten folgt eine Leerzeile.
Dann schließt sich ein zweiter Block mit fester Spaltenbreite an, in der die Kürzel aus den Spaltenüberschriften im ersten Block erklärt werden. Auch dieser Block endet mit einer Leerzeile.
Der dritte Block, der mit dem Wort Kommentare beginnt, verwendet ebenfalls feste Spaltenbreiten. Hier ist ein Beispiel für einen solchen dritten Block:
Kommentare
"Datenpunktname Startzeit Endzeit Kommentar "
"KKB.1112* 13.06.2023 19:00 13.06.2023 20:00 Leicht erhöhte Messwerte, kein Einfluss des Kraftwerks"
"KKB.3121* 10.06.2023 08:00 11.06.2023 09:00 Leicht erhöhte Messwerte, kein Einfluss des Kraftwerks"
Auswertung der Zeitreihe
Ich habe ein kleines Python-Programm geschrieben, das die gesamte Datenserie der KFÜ-Messwerte herunterlädt und für ein paar Messstellen ein Diagramm zeichnet. Der Einfachheit halber habe ich alle Datensätze heruntergeladen - da sie sich zeitlich überschneiden, wäre das eigentlich nicht notwendig.
Die Funktion read_one_file ruft eine CSV-Datei über URL aus dem Open-Data-Portal ab und erstellt daraus einen Pandas Dataframe. Die Hauptlogik ruft alle Datensätze der Datenserie ab (siehe auch Blog-Beitrag »Datenserien«). Aus jedem Datensatz wird die Distribution von Typ CSV ermittelt. Die Adressen aller CSV-Dateien werden in der Liste csv_files gesammelt.
Diese Liste wird durchlaufen und die erhaltenen Dataframes werden zu einem großen Dataframe verschmolzen (pd.concat). Da sich - wie eingangs geschildert - die Messwerte in den Dateien überschneiden, ist der Aufruf der Funktion drop_duplicates wichtig.
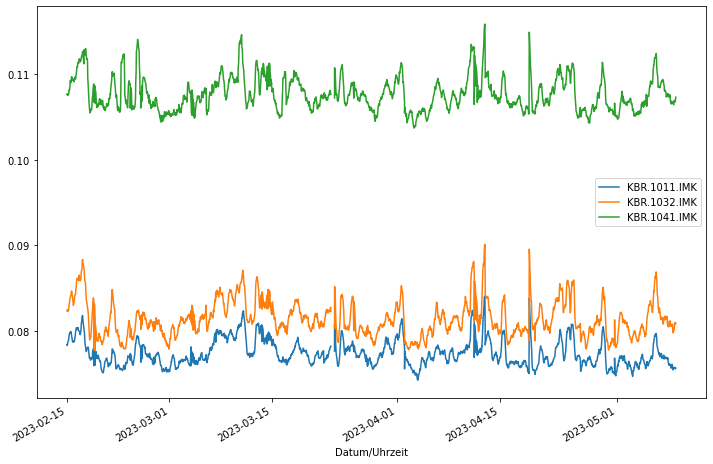
Schließlich wird für drei Stationen ein Diagramm gezeichnet. Damit das Diagramm nicht so “zappelig” ist, wird ein gleitender Durchschnitt mit einer Fenstergröße von 12 (Stunden) verwendet.
import requests
import pandas as pd
import matplotlib.pyplot as plt
def read_one_file(url):
# Die zweite Zeile enthält keine verwertbaren Informationen und wird übersprungen.
df = pd.read_csv(url,encoding='latin1',delimiter=';',decimal=',',skiprows=[1])
# Datum und Uhrzeit umwandeln
df['Datum/Uhrzeit'] = pd.to_datetime(df['Datum/Uhrzeit'], format='%d.%m.%Y %H:%M:%S',errors='coerce')
# Nur Zeilen mit gültiger Zeitangabe sind echte Messwerte. Die übrigen Zeilen können verworfen werden.
df.dropna(subset=['Datum/Uhrzeit'], inplace=True)
return df
# eine Liste mit den Adressen aller CSV-Dateien der KFÜ
csv_files = []
url = 'https://opendata.schleswig-holstein.de/api/action/package_show?id=kfue-7t'
response = requests.get(url)
data = response.json()
package_ids = [item['__extras']['subject_package_id'] for item in data['result']['relationships_as_object']]
for id in package_ids:
url = 'https://opendata.schleswig-holstein.de/api/action/package_show?id=' + id
response = requests.get(url)
data = response.json()
resource = next((res for res in data['result']['resources'] if res.get('format') == 'CSV'), None)
csv_files.append(resource['url'])
# erste CSV-Datei einlesen
df = read_one_file(csv_files[0])
# alle weiteren CSV-Dateien einlesen und anhängen
for f in csv_files[1:]:
df2 = read_one_file(f)
df = pd.concat([df, df2], ignore_index=True).drop_duplicates()
df.set_index('Datum/Uhrzeit', inplace=True)
selected_columns = ['KBR.1011.IMK', 'KBR.1032.IMK','KBR.1041.IMK']
df_selected = df[selected_columns]
rolling_mean = df_selected.rolling(window=12).mean()
rolling_mean.plot(figsize=(12,8))
plt.show()
Das Ergebnis sieht folgendermaßen aus: