Maschinenlesbare Statistiken
Viele Statistiken werden als PDF-Dokumente veröffentlicht. Für eine Nutzung der Daten ist das äußerst ungünstig. Dafür benötigen wir maschinenlesbare bzw. maschineninterpretierbare Daten. Doch wie lassen sich komplexe statistische Auswertungen eigentlich maschinenlesbar machen?
Bei manchen Statistiken ist es einfach: eine Spalte mit dem Datum und eine zweite mit der Anzahl - fertig. Es gibt aber wesentlich komplexere Statistiken, z.B. die SchwbR Bestandsstatistik (Antragsbestands und der bewilligten und abgelehnten Anträge nach dem Schwerbehindertenrecht).
Um ein Gefühl dafür zu bekommen, wie man eine kompliziertere Statistik sinnvoll maschinenlesbar gestalten kann, habe mich mir die Elterngeld-Widerspruchstatistik vorgenommen - nicht ganz einfach, aber auch nicht gleich so kompliziert wie die eben erwähnte SchwbR Bestandsstatistik.
Die Tabelle in der PDF-Datei sieht folgendermaßen aus:
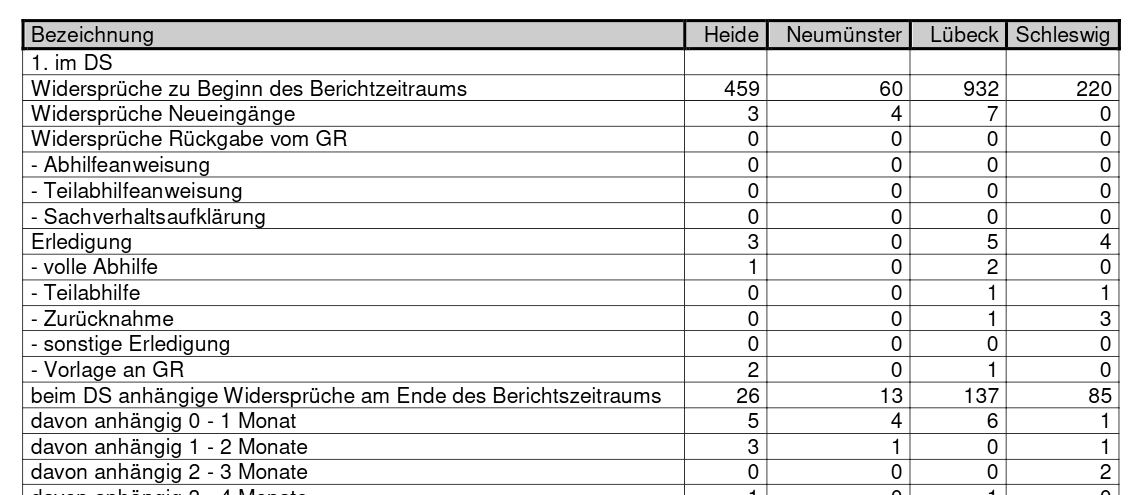
Die erste (weiße) Zeile ohne Zahlen enthält den Hinweis, dass sich die folgenden Zeilen auf im DS beziehen. Was DS bedeutet, werde ich noch in Erfahrung bringen und ergänzen. Es gibt noch einen zweiten Teil in der Tabelle beim GR. Hier vermute ich, dass es sich um die Fälle handelt, die vor Gericht verhandelt werden. Auch das prüfe ich noch nach. Viele Angaben gibt es also doppelt, z.B. Widersprüche zu Beginn des Berichtzeitraums. Da müssen wir aufpassen, ob es sich um die Zahl für im DS oder die Zahl für beim GR handelt.
Außerdem erkennt man, dass es eine Hierarchie gibt. Die Widersprüche Rückgabe vom GR werden in drei Fälle untergliedert, die Erledigung in fünf Fälle und für die beim DS anhängige Widersprüche am Ende des Berichtszeitraums wird in neun Stufen unterschieden, wie lange das Verfahren schon dauert.
Eine PDF-Datei enhält nur die Zahlen für einen Monat. Interessant sind aber längere Zeitreihen. Für die maschinenlesbare Version sollten wir also gleich vorsehen, dass der Monat als eigener Wert auftaucht.
Mein Vorschlag ist, die Tabelle zu transponieren. Dann lässt sich (mit einem Frictionless Table Schema) für jede Spalte genau beschreiben, welcher Wert dort enthalten ist. Auch Prüfregeln (die Zahl in der Spalte Erledigung muss gleich der Summe der fünf nachfolgenden Spalten sein) lassen sich so angeben. Aus den vier Spalten für den Dienstsitz werden dann vier Zeilen. Der Name des Dienstsitzes kommt in eine eigene Spalte. Auch der Monat bekommt eine Spalte. Damit ergibt sich folgender Aufbau:
| Monat | Dienstsitz | Widersprüche zu Beginn des Berichtzeitraums | Widersprüche Neueingänge | Widersprüche Rückgabe vom GR | - Abhilfeanweisung |
|---|---|---|---|---|---|
| 2023-01 | Heide | 449 | 10 | 0 | 0 |
| 2023-01 | Neumünster | 54 | 6 | 0 | 0 |
| 2023-01 | Lübeck | 926 | 6 | 0 | 0 |
| 2023-01 | Schleswig | 216 | 4 | 0 | 0 |
Bleibt noch das Problem der langen und uneindeutigen Spaltenbezeichnungen. Hier würde ich kurze und eindeutige (Problem im DS und beim GR) Abkürzungen definiert und im Table Schema den bisherigen Text als Titel angibt. Damit sehen die ersten Spalten der Tabelle so aus:
| Monat | Dienstsitz | DS_Beginn | DS_Neu | DS_vomGR | DS_vomGR_Abhilf |
|---|---|---|---|---|---|
| 2023-01 | Heide | 449 | 10 | 0 | 0 |
| 2023-01 | Neumünster | 54 | 6 | 0 | 0 |
| 2023-01 | Lübeck | 926 | 6 | 0 | 0 |
| 2023-01 | Schleswig | 216 | 4 | 0 | 0 |
Im Table Schema wäre die Definition für die ersten drei Spalten:
[ {
"name": "Monat",
"type": "yearmonth"
},
{
"name": "Dienstsitz",
"type": "string",
"constraints": { "enum": ["Heide", "Lübeck", "Neumünster", "Schleswig" ] }
},
{
"name": "DS_Beginn",
"title": "Widersprüche im DS zu Beginn des Berichtzeitraums",
"description" : "..."
"type": "integer"
} ]
Die Einschränkung für die Werte beim Dienstsitz müsste man natürlich entfernen, wenn man das Prinzip auf weitere Bundesländer ausweiten wollte. Schön wäre an das Stelle eigentlich die URI der Dienststelle im Behördenverzeichnis.
Mein kompletter Vorschlag als CSV-Datei ist hier zu finden: beeg-widerspruch.csv
Ist meine Idee sinnvoll? Kann man so etwas damit anfangen? Ich freue mich über Hinweise und Kommentare!