Wie läuft’s mit den Daten? - Reibungslos!
Dateien, insbesondere CSV-Dateien sind immer wieder bunte Wundertüten. Man weiß nie so genau, was einen genau erwartet. Zu verschieden sind Zeichenkodierungen, Spaltentrenner, Dezimaltrennzeichen etc. Auch die Spaltenüberschriften halten immer wieder (meist unschöne) Überraschungen bereit, da man oft gar nicht weiß, was genau gemeint ist.
Möchte man solche CSV-Dateien maschinell verarbeiten, muss man alle diese Angaben zunächst von Hand ermitteln und dann dem verarbeitenden Programm mitteilen - sei es in Dialogfenstern oder händisch kodiert. Kombiniert man mehrere CSV-Dateien, muss man meist für jede einzelne Datei die Angaben neu ermitteln und aufschreiben. Es gibt zwar Heuristiken, die mehr oder weniger gut Zeichensatz und Trennzeichen bestimmen können und auch gängige Spaltenbezeichner (id, longitude und latitude) finden. Ganz ohne Handarbeit geht es aber meistens nicht.
Genau an der Stelle setzt Frictionless Data an. Diese Initiative der Open Knowledge Foundation bietet Standards und Software, um Daten maschinen-interpretierbar zu beschreiben. Im Open-Data-Portal Schleswig-Holstein gibt es nun erste Datensätze mit diesen Beschreibungen. Wie funktioniert das und was hat man davon?
Ein so beschriebener Datensatz ist Marktplatz - Autos mit der Anzahl der Autos auf dem Marktplatz in St. Peter-Ording im Jahr 2022. Unterhalb der üblichen CSV-Datei findet man im Portal bei den Distributionen auch die JSON-Datei mit der Frictionless Tabular Data Resource.
Wenn die Frictionless Software auf dem Computer installiert ist, reicht nun ein einziger Befehl, um sich z.B. die ersten 10 Einträge aus diesem Datensatz anzeigen zu lassen:
frictionless extract --limit-rows 5 https://opendata.schleswig-holstein.de/dataset/f4a2ea78-86c5-445a-8e5e-fe88c8ec37c6/resource/aeb7c5da-63a5-4ba7-adc2-388bedcb9b07/download/marktplatz_autos_2022.json
Das Ergebnis sieht so aus:
=================== ================== ====== =====
timestamp area sensor value
=================== ================== ====== =====
2022-01-01 01:00:58 Marktplatz - Autos count 1.0
2022-01-01 01:02:01 Marktplatz - Autos count 2.0
2022-01-01 01:03:04 Marktplatz - Autos count 2.0
2022-01-01 01:05:24 Marktplatz - Autos count 3.0
2022-01-01 01:06:11 Marktplatz - Autos count 5.0
=================== ================== ====== =====
Zum Vergleich hier der Beginn der CSV-Datei:
timestamp;area;sensor;value
01.01.2022 01:00:58;Marktplatz - Autos;count;1,0
01.01.2022 01:02:01;Marktplatz - Autos;count;2,0
01.01.2022 01:03:04;Marktplatz - Autos;count;2,0
01.01.2022 01:05:24;Marktplatz - Autos;count;3,0
01.01.2022 01:06:11;Marktplatz - Autos;count;5,0
Mit den Trennzeichen, dem typisch deutschen Komma, der deutschen Schreibweise der Zeit - mit allem muss man sich nicht mehr beschäftigen, da es bereits in der Frictionless Data Beschreibung enhalten ist.
Ebenfalls mit einem einzigen Befehl kann man prüfen, ob beim Erstellen der CSV-Datei ordentlich gearbeitet wurde:
frictionless validate https://opendata.schleswig-holstein.de/dataset/f4a2ea78-86c5-445a-8e5e-fe88c8ec37c6/resource/aeb7c5da-63a5-4ba7-adc2-388bedcb9b07/download/marktplatz_autos_2022.json
Hier zeigt einem das Programm neben dem entscheidenden valid noch einige Informationen zur Datei an.
Alles ziemlich reibungslos! 😀
Wie funktioniert das?
Vielleicht erinnert man sich noch, dass bei DCAT-AP.de zu jedem Dataset eine odere mehrere Distributionen gehören. In diesem Fall gibt es zum Dataset marktplatz-autos-2022 eine Distribution als CSV-Datei Markplatz_Autos_2022.csv. Als weitere Distribution wird nun die Frictionless Tabular Data Resource marktplatz_autos_2022.json ergänzt. Diese beschreibt den syntaktischen Aufbau der CSV-Datei und den Ort, wo sie zu finden ist. Außerdem beschreibt sie den inhaltlichen Aufbau CSV-Datei, also die Spalten einschließlich Datentypen. Das ist das Table Schema.
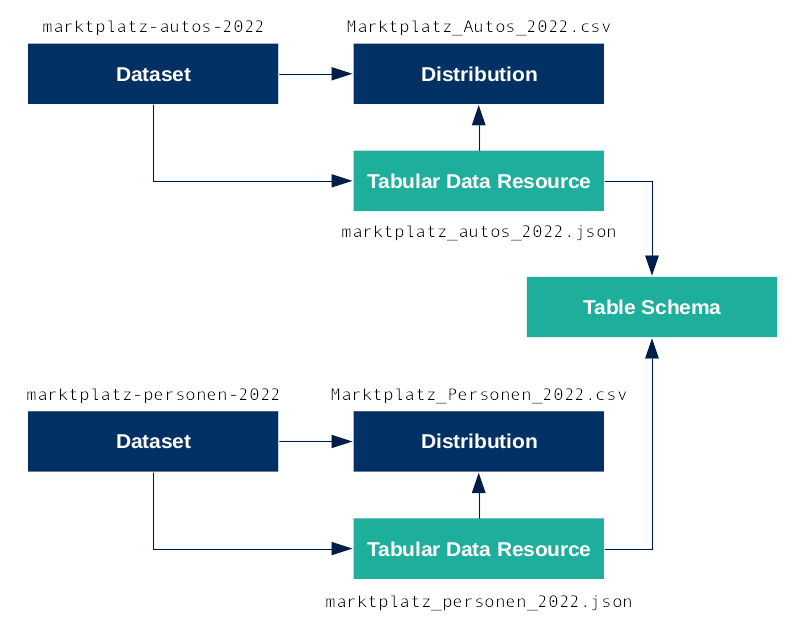
Der Clou ist, dass man auf dieses Table Schema auch von weiteren Tabular Data Resources aus verweisen kann, die den selben Aufbau haben. Das könnten verschiedene Jahre der Daten sein oder wie hier im Beispiel der Datensatz markplatz-personen-2022. Auch der hat eine Tabular Data Resource marktplatz_personen_2022.json, die auf die CSV-Datei Markplatz_Personen_2022.csv und das Table Schema zeigt.
Ein Beispiel in Python
Sind die Daten entsprechend beschrieben, genügen wenige Zeilen Code, um die Daten in einem Programm weiter zu verarbeiten. Man kann sich z.B. mit etwas Python-Code eine Karte des Datensatzes zeichnen. Dabei muss man noch nicht einmal angeben, in welcher Spalte die geographischen Informationen stehen. In diesem Beispiel sind zwei Datensätze angegeben, für die man eine Karte zeichnen lassen kann. Wenn man die Kommentierung ändert, bekommt man den anderen Datensatz zu sehen.
from frictionless import Resource
import pandas as pd
import geopandas
#r = Resource('https://opendata.zitsh.de/frictionless/haltestellen-smartes-dorfshuttle-stand-01-2022.json')
r = Resource('https://opendata.zitsh.de/frictionless/v_badegewaesser.resource.yml')
df = r.to_pandas()
longitudeField = [f.name for f in r.schema.fields if f.get('rdfType') == 'https://schema.org/longitude'][0]
latitudeField = [f.name for f in r.schema.fields if f.get('rdfType') == 'https://schema.org/latitude'][0]
gdf = geopandas.GeoDataFrame( df, geometry=geopandas.points_from_xy(df[longitudeField], df[latitudeField]))
gdf.plot()
Wenn bei den ersten drei Zeilen Fehler auftreten, dann sind noch nicht alle Python-Bibliotheken installiert. Insbesondere frictionless hat man vermutlich noch nicht auf dem System. Die Pakete lassen sich in etwa so installieren:
pip install pandas geopandas frictionless
Ausblick
Wie man an diesen Beispielen gesehen hat, macht Frictionless Data die Arbeit mit Daten deutlich einfacher. Wenn man die Beschreibungen hat, lassen sich noch viel mehr Dinge damit anstellen. Indem man die Validierung automatisiert, kann man eine hohe Qualität der Daten sicherstellen. Die präzise Beschreibung der enthaltenen Daten und ihrer Datentypen verhindert Fehler bei der Verarbeitung (indem man den Inhalt einfach rät) und spart Nachfragen. Auch bei der Suche können diese Informationen eingesetzt werden (“Zeige mir Daten, die einen geografischen Bezug enthalten.”) Und von Hand schreiben muss man die Beschreibungen auch nicht, dafür gibt es von Frictionless Data auch praktische Webanwendungen.